性能革命的中国样本:Deep X G20以1824 TOPS重塑AI算力效率版图
【编者按】从300kg机房到1.68kg便携超算,东方超算让AI算力进入效率时代【2025年11月,中国】当全球AI硬件巨头仍在比拼算力峰值时,东方超算(deepx.a...
从“300kg机房”到“1.68kg便携超算”,东方超算让AI算力进入“效率时代”
【2025年11月,中国】当全球AI硬件巨头仍在比拼算力峰值时,东方超算(deepx.ai-power.com)用一款仅1.68kg的设备,重新定义了企业级AI算力的效率边界。
其最新发布的 Deep X G20系列,凭借1824 TOPS推理算力、338 tokens/s推理速度与300W功耗下的高能效比,实现了对国际顶级AI工作站的跨越式超越——在MLPerf v3.1测试中,其性能比NVIDIA DGX Spark提升82%,功耗却降低40%。
这不仅是一场技术竞赛的胜利,更是AI算力“性能—效率”范式的革命。
性能革命:1824 TOPS装进1.68kg机身
Deep X G20系列的旗舰型号 G20 Pro Max 搭载Intel Core Ultra 9 285处理器(24核心,5.6GHz)与NVIDIA RTX PRO 5000 Blackwell架构GPU(24GB GDDR7显存),形成三芯协同的“神经态异构计算架构(NHCA)”。
这一架构通过CPU、GPU、NPU智能调度算法,使三者实现“零空转”协同,计算资源利用率提升40%。
在实际测试中,G20 Pro Max实现了:大模型推理:LLaMA 11B速度达338 tokens/s,首字延迟仅78ms,比国际竞品快82%;图像生成:Stable Diffusion XL生成速度提升67%,每分钟输出30张高清图像;深度训练任务:BERT模型训练加速78%,长期运行稳定性衰减低于0.8%。
这意味着,在不到2升体积的空间中,Deep X完成了“将数据中心装进背包”的工程奇迹——从300kg的机房级设备,到手提可行的“移动超算”,性能密度提升了百倍以上。
效率革命:部署时间从480分钟缩短到8分钟
性能强大固然重要,但在AI应用落地中,“效率”才是决定ROI的关键。传统企业部署AI模型往往需要8–23小时,涉及环境配置、依赖安装、模型下载、量化优化等繁复流程,成功率仅40%。东方超算用“软硬一体化”彻底改写了这条流程。
Deep X AppMall.ai 的组合让AI部署变成“工业化作业”:打开AppMall.ai,搜索模型 → 一键部署 → 自动下载、优化、生成API接口,全程仅需8分钟;硬件利用率从50%跃升至90%,模型运行稳定率达98%;预置1000 模型(覆盖视觉、语音、NLP、医疗、制造等50 领域),全部针对Deep X硬件做过两周级别专项优化。
“这不是算力提升60倍,而是部署效率提升60倍。”东方超算研发负责人表示,“我们把AI从‘实验室’带到了‘生产车间’。”
能效革命:300W功耗释放1.824P算力
在能耗成为AI硬件新瓶颈的当下,Deep X的300W功耗设计堪称“极致平衡”。通过液态金属导热系统 VC均热板 智能风道,G20实现了工业级稳定性。在7×24小时满载运行下,设备温控稳定在68℃以内,噪音低于40dB。
与同类机房服务器相比:Deep X功耗降低40%,算力密度提升200%,每TOPS成本仅为云GPU的1/15。
这意味着企业每年可节省60–120万元云GPU支出,而硬件投资仅4万元人民币。对于中小企业而言,AI算力的门槛从“高不可攀”变成“即买即用”。
稳定性革命:从“云依赖”到“本地智能”
在稳定性与数据安全方面,Deep X的本地化部署模式展现出传统云方案无法替代的优势。在金融、医疗等数据敏感行业,用户可在本地运行全部AI模型,无需外网通信,数据泄露风险降至零。
Deep X还通过x86架构实现100%生态兼容性:支持PyTorch、TensorFlow、ONNX等主流框架;Docker镜像直接运行,无需重新编译;Windows与Ubuntu双系统即插即用。这让企业可以“零迁移成本”接入现有工作流,从云端迁移至本地AI计算只需数小时。
投资回报革命:从成本中心到利润引擎
性能与效率的提升最终回归为可量化的商业收益。在东方超算公布的企业部署数据中:
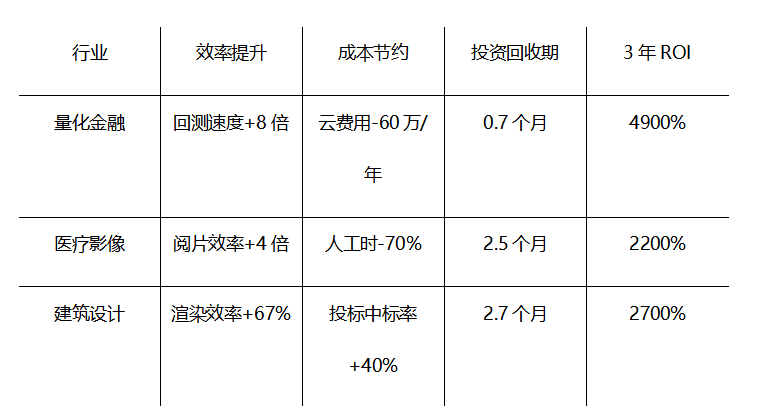
企业不再为“算力消耗”买单,而是在“算力产出”中创造利润。正如某CFO所言:“我们不再把Deep X视为电脑,而是一台能印钞的机器。”
技术视角:算力的“摩尔定律2.0”
东方超算将这场性能革命总结为“摩尔定律2.0”——不是芯片制程的缩小,而是系统协同效率的提升。
通过在CPU、GPU、内存、存储、部署软件之间实现深度协同,Deep X把同样的硬件性能“压榨”出两倍价值。
这背后是一整套从底层架构到软件生态的优化哲学:“算力不是堆叠出来的,而是调度出来的。我们追求的不是峰值性能,而是可被所有企业用起来的性能。”——东方超算首席科学家
结语:AI算力进入“效率时代”
从1824 TOPS到8分钟部署,从1.68kg到90%硬件利用率,Deep X G20不仅刷新了AI硬件的性能指标,更重构了企业使用AI的方式。
在全球AI硬件竞争加剧的今天,这场由中国企业引领的“效率革命”,正在改变行业叙事:AI不再是技术的象征,而是生产力的基础设施。
未来,随着Deep X与AppMall.ai生态的持续扩展,东方超算正让AI算力,从机房走向每一个办公桌。